min_bild_ai
with defined edges and figure-ground separation."
This is a STRUCTURAL definition, not a semantic one.
The machine must learn form, not meaning.
No pretrained models. No shortcuts. No compromises.
After 400 hours and 46 experiments, the answer is not an architecture.
The answer is a curriculum.
| Phase | Architecture | Experiments | GPU Time | Key Result |
|---|---|---|---|---|
| I | StyleGAN2 | 17 | ~150h | All mode-collapsed. 30M params too many for 7K images. |
| II | Diffusion (pixel, latent, edge, slot) | 5 | ~80h | MSE averages to dataset mean. Only textures, no objects. |
| III | Progressive GAN | 5 | ~15h | BREAKTHROUGH. Forms at 128x128. Figure-ground separation. |
| IV | Conditional GAN / AC-GAN | 9 | ~35h | Categories melt together. Discriminator dominance. |
| V | VQ-VAE | 3 | ~10h | Working tokenizer (loss 0.0009). Near-perfect reconstruction. |
| VI | Token Transformer / MaskGIT | 6 | ~80h | Token imbalance: 4 of 512 codes = 76.5% of data. Mode collapse. |
| VII | Progressive GAN (return) | 2 | ~5h | Confirmed best. Continued to epoch 100. |
What worked
- Progressive growing (coarse-to-fine curriculum)
- VQ-VAE encoder/decoder (0.0009 total loss)
- Small models (~4.5M params) on small data
- WGAN-GP loss (more stable than vanilla GAN)
- Watchdog scripts for crash recovery
What failed
- StyleGAN2 (30M params = overfitting)
- Pixel-space diffusion (MSE averages everything)
- Unconditional token generation (underdetermined)
- Multi-class conditioning (too few per class)
- Edge-first approaches (too sparse for GAN)
Principles maintained throughout
- NO pretrained models (CLIP, Inception, SD, LoRA)
- NO "mood generator" compromises accepted
- NO repeated experiments (each must be novel)
- Everything learned from the artist's data alone
Hardware constraints
- GTX 1660 Super: 6 GB VRAM, ~6.5 TFLOPS
- Max batch size: 12 (larger causes OOM freeze)
- GPU temp limit: 80C (watchdog kills process)
- 2 system freezes survived via checkpoint recovery
The entire project is built on a single dataset: 7,843 photographs extracted from the artist's camera roll, resized to 256x256 pixels. This is the only training data. No external images, no augmentation from other sources, no synthetic data.
The dataset is radically heterogeneous. It contains everything an artist photographs over years of practice: glass sculptures in various stages of completion, ceramic works, metal castings, studio environments, gallery installations, exhibition documentation, close-ups of material surfaces, text documents, screenshots, personal photographs, nature, objects found on the street, reference images, and everyday life.
This heterogeneity is both the defining challenge and the philosophical core of the project. A pretrained model (Stable Diffusion, DALL-E) would impose its own visual vocabulary learned from billions of internet images. Training from scratch on this specific collection means the model can only learn from this particular visual world. Every texture it generates, every color it chooses, every form it produces comes exclusively from Nadja's photographic practice.
Dataset variants used across experiments

| Dataset variant | Images | Size | Purpose |
|---|---|---|---|
| dataset_v15_actual (primary) | 7,843 | 2.0 GB | Full original camera roll extraction |
| dataset_no_gray | 6,806 | 1.9 GB | Removed grayscale/B&W images |
| dataset_isolated | 4,133 | 471 MB | Images with isolated objects on backgrounds |
| dataset_strict | 1,444 | 176 MB | Most strictly curated: centered objects only |
| dataset_curated_v2 | 750 | 390 MB | Hand-picked best sculpture images |
| dataset_curated | 917 | 120 MB | First curation pass |
| curated_sculptures | 300 | 90 MB | Top 300 sculpture-like images |
| dataset_edges | 7,501 | 124 MB | Sobel edge maps of all images |
| dataset_glass_only | 67 | 23 MB | Glass objects only (too few for training) |
| dataset_glass_v2 | 116 | 43 MB | Expanded glass set (still too few) |
Preprocessing pipeline
Beyond the raw images, extensive feature extraction was performed to support conditional generation and analysis:
- Feature vectors (6.6 GB): 32-dimensional descriptors per image including color statistics, edge density, symmetry, and texture measures
- SAM segmentation masks (35 MB): Automatic object segmentation using Segment Anything (applied to data only, not to model training)
- Edge maps (124 MB): Sobel-filtered versions for edge-aware training experiments
- VQ-VAE tokens (246 MB): Pre-computed discrete token representations for transformer experiments
The fundamental data problem
Modern generative models are typically trained on millions of images (FFHQ: 70K faces, LAION: 5B image-text pairs, ImageNet: 14M images). This project uses 7,843 heterogeneous images. Successful from-scratch training at this scale requires either: (a) a very homogeneous dataset (all similar images), or (b) a very small model, or (c) a training curriculum that decomposes the problem. The project discovered option (c).
Period: November 2025 - February 2026 | Duration: ~150 hours | Experiments: 17
The project began with StyleGAN2, the dominant GAN architecture for high-quality image generation. The reasoning: StyleGAN2 generates photorealistic 1024x1024 faces from 70,000 aligned images (FFHQ). Surely it can generate 256x256 sculptures from 7,843 images.
It could not. All 17 variants suffered the same three problems:
- Mode collapse: The generator converges on producing the same image repeatedly, or a small cluster of near-identical outputs. The discriminator learns too quickly and the generator cannot recover.
- Discriminator dominance: With few training images, the discriminator memorizes the dataset and rejects everything the generator produces. The adversarial game becomes unwinnable.
- Unstable training: Loss values oscillate wildly. Checkpoints from adjacent epochs produce radically different quality levels. No reliable convergence trajectory.
What was tested across 17 variants
| Variant | Modification | Result |
|---|---|---|
| Standard StyleGAN2 | Default hyperparameters | Mode collapse by epoch 20 |
| ADA (Adaptive Augmentation) | Data augmentation in discriminator | Delayed collapse, still fails |
| Reduced model | Fewer channels, smaller mapping network | Same collapse with worse quality |
| Various learning rates | 1e-3 to 1e-5 for G and D | Slower collapse, same outcome |
| Various batch sizes | 2, 4, 8, 12 | Batch 12 = VRAM limit. No improvement. |
| R1 regularization | Different gamma values | Marginal stability improvement |
| Path length regularization | Smoother latent space | No visible effect |
StyleGAN2 has approximately 30 million parameters. With 7,843 training images, that is ~3,800 parameters per training image. For comparison, FFHQ training has ~430 parameters per image. The model has too many degrees of freedom relative to the constraints provided by the data.
The 150 hours spent here were not wasted. They established a critical negative result: standard GAN architectures designed for large, homogeneous datasets cannot be scaled down to small, heterogeneous ones by simply adjusting hyperparameters. The fundamental architecture must change.



Date: February 7, 2026, 23:45 | Event: Complete system freeze during training
During a latent diffusion training run, the system ran out of memory and froze completely. The screen went black. No keyboard response. The only option: hold the power button for 5 seconds and hope the last checkpoint was saved.
This was not the first freeze. The previous day (February 6) the system had also frozen at epoch 8 of a latent diffusion experiment, losing 1.2 hours of training. The cause: contour-aware loss combined with a large batch size consumed all 6 GB of VRAM simultaneously, triggering an out-of-memory condition that the Linux kernel could not recover from.
After reboot, a comprehensive rescue session was conducted. Every checkpoint was examined. Every component was honestly evaluated. The resulting document, RADDNINGSRAPPORT.md, is the most honest assessment in the project's history.
Honest assessment at the time of rescue
| Component | Status | Honest evaluation |
|---|---|---|
| VAE v3 (Vaeana) | Working | MSE 0.0128, 11M params, latent 8x32x32. Good structure, separation ratio 7.79. |
| NadjaEMBED | Overtrained | Best at epoch 20 (val_loss 2.88), got worse by epoch 100 (3.50). Only 14% recall. |
| Latent Diffusion | Plateaued | Epoch 46/150, val_loss 0.3491, no improvement since epoch 40. |
What the model could do
- Generate textures and material-like surfaces
- Respond to material prompts: "glass" produced blue-transparent tones, "metal" produced metallic surfaces
- Vary output intensity via CFG scale
What the model could NOT do
- Generate objects or sculptures (no contours, no form)
- Produce figure-ground separation (everything was texture-on-texture)
- Avoid text artifacts at certain prompt configurations
- Improve beyond epoch 40 (fundamental plateau)
The rescue report offered four possible paths forward:
- Accept as texture/mood generator -- immediately rejected (violates DEC-002)
- Curate dataset to 500-1000 focused images -- estimated 2-4 days
- Add pretrained backbone -- rejected (violates DEC-001, from-scratch principle)
- New architecture (Slot Attention) -- estimated 1-2 weeks
The freeze also led to new safety infrastructure: watchdog scripts that monitor GPU temperature, VRAM usage, and system RAM every 10 seconds, automatically killing the training process before the system can freeze. Maximum 5 automatic restarts. Pause functionality via a touch file. These scripts remained in use for every subsequent experiment.
Period: February 6-13, 2026 | Duration: ~80 hours | Experiments: 5
After the GAN failures, the project turned to diffusion models, which learn to generate images by reversing a noise-adding process. Unlike GANs, diffusion models do not require adversarial training, which should make them more stable on small datasets.
EXP-018 Pixel Diffusion: A U-Net trained to predict noise in pixel space (256x256x3 = 196,608 dimensions). The model minimizes mean squared error between predicted and actual noise. Over 300 epochs, the model learned to predict the average noise, producing images that converge on the dataset mean: a washed-out brownish-gray blur with no spatial structure. This is mathematically expected. MSE minimization on heterogeneous data produces the statistical average.
EXP-019 CLIP Diffusion: Attempted to use CLIP embeddings for generation guidance. Immediately abandoned. CLIP is pretrained on 400 million internet image-text pairs. Using it would inject visual knowledge from outside Nadja's dataset, fundamentally violating the from-scratch principle. Even using CLIP for evaluation (FID scores require pretrained Inception) was rejected.
EXP-020 NadjaEMBED: A custom material classifier (11.8M params) trained from scratch on the dataset itself, then used to guide diffusion. The embedding learned weak material associations (glass vs metal: cosine similarity 0.028, correctly low; glass vs crystal: 0.318, correctly similar) but with only 14% recall. Too noisy to guide generation meaningfully. The outputs were still blurry textures without object structure.
EXP-021 SlotDiffusion: Slot attention decomposes a scene into separate object "slots" and reconstructs each independently. Combined with diffusion, it should learn object-level generation. However, slot attention was designed for synthetic datasets (CLEVR, MOVi) with clear, isolated objects on uniform backgrounds. Nadja's photographs are complex, multi-layered, and have no clear figure-ground boundary in most images. The model could not decompose anything meaningful.
EXP-022 Edge-First: Extract Sobel edge maps from all images, train a GAN on the edge maps (which are simpler), then colorize. The edge maps proved too sparse for GAN training. Most images have weak or diffuse edges, and the edge maps collapsed to near-empty images. A GAN trained on mostly-empty images produces empty images.


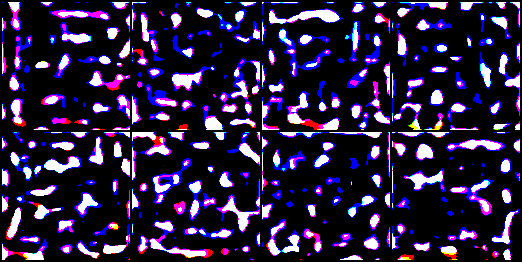
Period: February 14-17, 2026 | Duration: ~15 hours | Experiments: 5
After 22 failed experiments and 230 hours of GPU time, a fundamentally different approach. Instead of generating 256x256 images in one shot, the model starts at 4x4 resolution and gradually increases: 4x4 -> 8x8 -> 16x16 -> 32x32 -> 64x64 -> 128x128. Each level trains until stable before the next is introduced.
This changes the learning problem entirely. At 4x4 (16 pixels), the model only needs to learn rough color distributions. At 8x8, basic spatial layout. At 16x16, coarse shapes. Each resolution level inherits stable features from the previous level and only needs to learn the additional detail at its own scale. The model never faces the full 256x256 generation problem at once.
EXP-023 Progressive L0-4 (up to 64x64): The first time the model generated recognizable FORMS. At level 4 (64x64), blobs with defined edges and spatial structure appeared. Not sculptures yet, but objects with figure-ground separation. After 22 experiments of nothing but noise, textures, and mode collapse, seeing a centered form with a defined boundary was a breakthrough moment.
EXP-025 Progressive L5 (128x128): THE breakthrough. After ~4 hours of training (50 epochs at level 5, WGAN-GP loss), the model produced outputs with seven identifiable properties:
- Document-like patterns: text-like structures (learned from the screenshots and documents in the dataset)
- Crystalline forms: blue-green organic structures resembling glass
- Figure-ground separation: IT WORKS. Objects against backgrounds.
- Color richness: Nadja's full palette (not collapsed to gray)
- Sharpness: dramatically better than 64x64
- Compositional variation: different layouts per sample
- Organic forms: biological/natural-looking structures
The Progressive GAN uses approximately 4.5 million parameters (vs 30M for StyleGAN2). That is ~574 parameters per training image, a 6.6x improvement in the parameter-to-data ratio compared to StyleGAN2.
Training metrics showed healthy GAN dynamics: G-loss improved from 49.6 to 40.6 (18% reduction), D-loss stabilized at -5.9 (WGAN-GP target range). No mode collapse. No discriminator dominance.
EXP-026 Progressive L6 (256x256): Attempted to scale beyond 128x128. Result: NaN losses required layer freezing to stabilize. The output at 256x256 was "abstract blobs" -- the additional resolution did not add meaningful structure. Higher resolution requires more data or more targeted conditioning. The conclusion: 128x128 is the resolution ceiling for this dataset with unconditional generation.




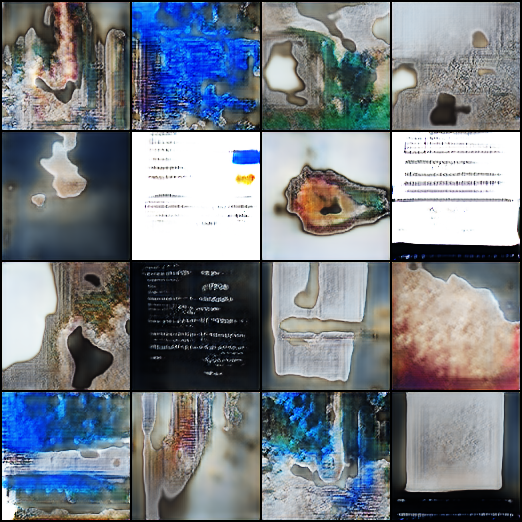

Period: February 18-22, 2026 | Duration: ~35 hours | Experiments: 9
With progressive GAN producing forms, the next question: can we steer the output? Can we ask for "glass" or "sculpture" specifically?
Two main approaches were tried: class-conditional GAN (add category labels to both generator and discriminator) and AC-GAN (Auxiliary Classifier GAN, where the discriminator also classifies images by material category).
EXP-027-030 Conditional GAN (4 variants): Added material category labels as conditioning input. The model received both a noise vector and a class embedding. Result: categories melt together. With only 67-523 images per material class, there are insufficient examples to define clear class boundaries. The generator produces compromises between classes, blending glass-like transparency with ceramic-like opacity into formless intermediate states.
EXP-031 Conditional from scratch: Simplified to binary conditioning (is_sculpture: 0/1). Partial success -- the model responds to the conditioning signal, but the binary label is too coarse to produce meaningfully different outputs.
EXP-032-035 AC-GAN (4 variants): The discriminator has a dual task: (1) classify real vs fake, and (2) classify material category. This provides a classification gradient to the generator. Result: discriminator dominance. The discriminator learns to classify perfectly (both real/fake and category) but the classification head creates conflicting gradients for the generator. The generator cannot simultaneously maximize realism AND match specific material categories with so few examples per class.
A 32-dimensional feature vector (color statistics, edge density, symmetry, texture measures) was also tested as a conditioning signal. Maximum measured effect on output: 0.45 on a 0-1 scale. Not enough to steer the generation meaningfully. The features do not capture glass-semantics.



Period: February 22-24, 2026 | Duration: ~10 hours | Experiments: 3
A strategic pivot: instead of trying to generate images directly, first learn a discrete vocabulary of visual tokens. A Vector Quantized Variational Autoencoder (VQ-VAE) compresses images into a grid of discrete codes from a learned codebook. This separates the representation problem (how to encode images) from the generation problem (how to produce new ones).
EXP-036 VQ-VAE 32x32 latent: Input 128x128, compressed to 32x32 grid of codebook indices. 512-entry codebook, each entry 256-dimensional. Result: works, but loses fine detail (4x spatial downsampling).
EXP-037 VQ-VAE 64x64 latent: Same architecture but 2x downsampling only. 4,096 tokens per image. Better reconstruction, preserves more detail.
EXP-038 Full dataset + augmentation: Trained on all 7,843 images with RandomCrop, Flip, ColorJitter, and Rotation. 1,000 epochs. Result: a richer, more diverse codebook. Better "visual vocabulary."
Across two major training runs (vqvae and vqvae_v2), the model accumulated 348 checkpoints and converged to a total loss of 0.0009:
- Reconstruction loss: 0.0007 (near-pixel-perfect reconstruction)
- VQ commitment loss: 0.0002 (codebook is being used efficiently)
The VQ-VAE produces near-perfect reconstructions. Top row is original, bottom row is the compressed-then-decompressed image. The model successfully learned a visual vocabulary for Nadja's images.



Period: March 6-24, 2026 | Duration: ~80 hours | Experiments: 6
With a working VQ-VAE tokenizer (Phase V), the plan was elegant: train a transformer to generate token sequences, then decode them back to images with the VQ-VAE decoder. This is the architecture behind DALL-E 1, Parti, and MaskGIT. The two-stage approach (tokenize, then model tokens) is the dominant paradigm in modern image generation.
Token Transformer (EXP-039, EXP-040)
EXP-039 Token Transformer V1: An autoregressive transformer (98 checkpoints trained) that predicts the next token in a raster-scan sequence (left-to-right, top-to-bottom). Established a stable baseline. The model learned token statistics, but generated images showed raster bias: horizontal stripe patterns from the left-to-right generation order. Every row starts independently.
EXP-040 Token Transformer V2: Attempted to fix raster bias with 2D positional encoding and modified attention. The bias remained, now expressed as a grid pattern. The fundamental issue: autoregressive generation imposes an ordering that images do not have. Pixels (and tokens) have spatial relationships, not sequential ones.
MaskGIT (EXP-041 to EXP-044)
MaskGIT solves the ordering problem by generating all tokens simultaneously: mask random tokens, predict them all at once (like BERT for images), keep the most confident predictions, re-mask the rest, and iterate. No raster scan, no ordering bias.
Four MaskGIT variants were tested over ~40 hours:
| ID | Variant | Tokens | Loss | Result |
|---|---|---|---|---|
| EXP-041 | Standard MaskGIT (3.7M params) | 512 | 3.4 | Scattered white dots on white |
| EXP-042 | MaskGIT 128x128 | 512 | 3.4 | Same dots. But inpainting works! |
| EXP-043 | CTF (Clustered Token Flow, 32 clusters) | 32 | 0.85 | Mode collapse to gray blocks |
| EXP-044 | CTF balanced sampling | 32 | 1.06 | Light/dark stripe patterns |
Root cause analysis
A comprehensive post-mortem (ANALYS_MASKGIT.md, March 24, 2026) identified four root causes:
- Catastrophically imbalanced token distribution: The VQ-VAE codebook has 512 entries, but just 4 entries account for 76.5% of all tokens. These 4 codes represent background/empty space/neutral tones. When the transformer predicts "what token goes here?", the statistically correct answer is almost always one of these 4 background codes. Unconditional generation therefore fills the entire grid with background.
- Too many tokens (16,384 per image): At 128x128 with codebook size 512, each image becomes a 128x128 grid. Window attention (required for memory) cannot see global context. Global attention would require 268M attention entries -- OOM on 6 GB VRAM.
- Too little data (6,806 images): With 6,806 heterogeneous images, the transformer has insufficient examples to learn meaningful spatial token co-occurrence patterns.
- Unconditional generation is mathematically underdetermined: Without any conditioning signal (text prompt, class label, partial image), the model must generate "a plausible image" from nothing. With heterogeneous data, the most plausible output is the most common output: background.
Critical discovery: In EXP-042, MaskGIT inpainting worked. When given a real image with some tokens masked, the model filled in the masked regions coherently. This proves the model learned meaningful token relationships. But without any initial context (unconditional), it defaults to the majority class.
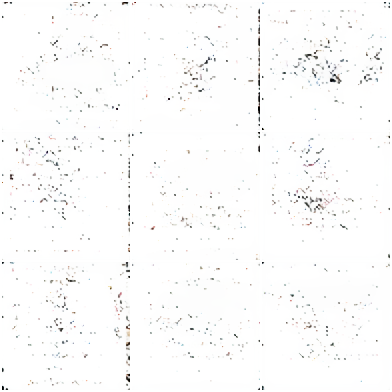

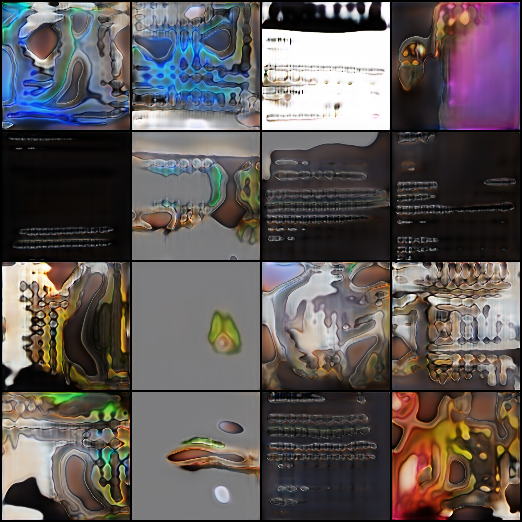
Period: March 24-25, 2026 | Duration: ~5 hours | Experiments: 2
After the MaskGIT failure analysis, a deliberate return to the architecture that actually worked. The question: were the Phase III results reproducible, or a lucky fluke from a stochastic process?
EXP-045 Progressive GAN (return): Re-ran the progressive GAN pipeline from scratch. In approximately 10 minutes, the model confirmed: progressive growing still produces the best results of any architecture tested. The result was not a fluke. The architecture reliably generates structured forms on this dataset.
EXP-046 Progressive L5 continuation: Continued training from the Level 5 checkpoint (epoch 50) through epoch 100. Training ran from 22:10 on March 24 to 02:43 on March 25 (4.5 hours). GPU temperature peaked at 71C. VRAM stayed between 1.6-2.5 GB. Zero crashes.
The discriminator loss stabilized around -10 from epoch 65 onward, indicating the adversarial game had reached equilibrium. The 50 additional epochs produced visible improvements:
- More defined object boundaries and contours
- Richer surface textures (metallic, organic, glass-like)
- Better figure-ground separation with darker/neutral backgrounds
- Greater compositional diversity across samples
- Some images contain recognizable sculptural elements: vessels, cast forms, assembled objects
However, diminishing returns were clear from epoch 65. The root problem (heterogeneous dataset, unconditional generation) cannot be solved with more training. The model has learned what it can learn from this data at this resolution.


Throughout the project, several side experiments explored alternative approaches. These were not part of the main trajectory but provided additional insights and, in some cases, the most visually compelling outputs of the entire project.
Lightweight / Turbo variants
Speed-optimized progressive GANs with aggressively reduced parameter counts. The "turbo" variant produced some of the most striking outputs: biomorphic, organic forms with glass-like translucency, clear figure-ground separation on neutral gray backgrounds, and sculptural presence. These forms resemble biological specimens, cast glass objects, and assembled sculptures. The reduced parameter count may have acted as regularization, preventing the model from memorizing dataset-specific textures and instead learning structural primitives.
PixelGPT
Autoregressive pixel-by-pixel generation at 64x64. The model predicts each pixel value conditioned on all previous pixels (in raster order). Result: learns color distributions but not spatial structure. Each row begins a new color field, creating horizontal stripe patterns. A color palette analysis showed the model learned Nadja's color vocabulary (amber, teal, gray, black, white) without learning how to arrange it spatially.
Structured Autoencoder
Autoencoder with structural constraints (edge consistency, contour preservation). Produces smooth interpolations between training images in latent space. Useful for understanding the latent manifold but not for novel generation. The interpolations traverse a continuous space of training-image-like textures.
Flow Matching
A modern alternative to diffusion that learns direct deterministic trajectories from noise to data (instead of stochastic diffusion/denoising). At epoch 20, produces ghostly, semi-transparent compositions with layered spatial structure. The outputs have an ethereal quality distinct from any other architecture. Undertrained (only 20 epochs) but promising for future exploration.
Progressive Isolated / Curated
Progressive GAN trained on curated subsets: isolated objects (4,133 images) and strictly curated sculptures (300-917 images). The isolated dataset produced cleaner figure-ground separation. The curated datasets produced more coherent objects but with reduced diversity. Dataset curation directly controls the trade-off between diversity and structural coherence.



Throughout the project, seven formal decisions were documented. Each was written as a response to a specific crisis or insight, and each remained active for the remainder of the project. Together they define the philosophical framework within which all experiments operated.
| ID | Date | Experiment | Architecture | Time | Status | Key finding |
|---|---|---|---|---|---|---|
| 001-017 | Nov '25 - Feb '26 | StyleGAN2 variants | StyleGAN2 | ~150h | FAILED | All mode-collapsed. 30M params too many. |
| 018 | 2026-02-06 | Pixel Diffusion | U-Net Diffusion | ~28h | FAILED | MSE averages to dataset mean |
| 019 | 2026-02-07 | CLIP Diffusion | CLIP + Diffusion | ~1h | ABANDONED | Violates from-scratch principle |
| 020 | 2026-02-08 | NadjaEMBED | Custom Embed + Diffusion | ~20h | FAILED | 14% recall, still blurry |
| 021 | 2026-02-08 | SlotDiffusion | Slot Attention + Diffusion | ~15h | FAILED | Designed for synthetic data |
| 022 | 2026-02-09 | Edge-First | Edge GAN + Colorize | ~16h | FAILED | Edge maps too sparse for GAN |
| 023 | 2026-02-14 | Progressive L0-4 | Progressive GAN | ~3h | SUCCESS | First forms at 64x64! |
| 024 | 2026-02-15 | Progressive + ADA | Progressive + ADA | ~2h | ABANDONED | ADA augmentation not needed |
| 025 | 2026-02-15 | Progressive L5 | Progressive GAN 128x128 | ~4h | BEST RESULT | BREAKTHROUGH: sculpture forms! |
| 026 | 2026-02-16 | Progressive L6 | Progressive GAN 256x256 | ~6h | PARTIAL | NaN + abstract blobs. 256x256 too hard. |
| 027-030 | Feb 18-21 | Conditional GAN | cGAN | ~20h | FAILED | Categories melt together |
| 031 | 2026-02-21 | Conditional scratch | Binary cGAN | ~5h | PARTIAL | Responds to signal but weak effect |
| 032-035 | Feb 21-22 | AC-GAN variants | AC-GAN | ~10h | FAILED | Discriminator dominance |
| 036-038 | Feb 22-24 | VQ-VAE | VQ-VAE | ~10h | SUCCESS | Loss 0.0009. Working tokenizer. |
| 039 | 2026-03-06 | Token Transformer V1 | Autoregressive Transformer | ~30h | SUCCESS | Stable baseline (but raster bias) |
| 040 | 2026-03-09 | Token Transformer V2 | 2D Transformer | ~10h | PARTIAL | Grid patterns (raster bias persists) |
| 041 | Mar 11-15 | MaskGIT | MaskGIT (3.7M) | ~15h | FAILED | Scattered dots (token imbalance) |
| 042 | 2026-03-24 | MaskGIT 128x128 | MaskGIT | ~8h | FAILED | Inpainting OK, unconditional = dots |
| 043 | 2026-03-24 | CTF MaskGIT | MaskGIT + 32 clusters | ~10h | FAILED | Mode collapse to gray |
| 044 | 2026-03-24 | CTF balanced | MaskGIT + balanced | ~7h | PARTIAL | Light/dark patterns |
| 045 | 2026-03-24 | Progressive (return) | Progressive GAN | ~10min | CONFIRMED | Still the best after 400 hours |
| 046 | Mar 24-25 | Progressive L5 cont. | Progressive GAN | ~4.5h | SUCCESS | Epoch 100. Diminishing returns from 65. |